
Visual language models (VLMs) present a new divergence in approaches to achieving state-of-the-art performance. The two complete opposites of VLM models exemplify this split: Pixtral Large, with its impressive 124B parameters and compute-heavy approach, versus TIGER-Lab's Mantis-Idefics, with just 8B parameters, a champion of efficiency.
Both generative AI models can analyze images and documents with greater efficiency than any other currently known solution. This capability enables us to tackle a variety of tasks, such as asking questions related to images, processing documents for comparison, and much more.
However, the big question is: which is more suitable and reasonable for enterprise-wide adoption of LLMs? In this article, we will compare the technical architecture and performance of the two models to help determine which one you should use.
Before diving into a technical comparison of the two models, we will briefly explain what these so-called visual language models are.
What are Visual Language Models?
Visual language models (VLMs) are generative AI models capable of reading, understanding, and analyzing information in images and documents, including charts, webpages, mathematical reasoning, and much more.These capabilities enable identifying errors, categorizing findings, answering questions about the information in these files, and even automating many human labor tasks.
For example, you can use these models to build a chatbot to ask and retrieve information about technical drawings (and automate tasks related to these), understand and compare insurance documents, analyze X-ray images to identify cancer, and more. As a result, these models are highly beneficial across many industries, such as healthcare, insurance, manufacturing, and beyond.
The Technical Architecture Face-Off Pixtral Large (124B) vs Mantis-Idefics2 (8B)
Pixtral Large (124B)
Core Architecture:
- 124B parameters
- 300GB+ GPU RAM requirement
- Enterprise-grade GPU clusters necessary
- ~37.5GB per billion parameters
- Long context window (128K tokens)
Technical Innovations:
- Novel ROPE-2D implementation
- Block-diagonal attention masks
- Native resolution processing
- Gating in FFN layers
- Full Chain-of-Thought (CoT) reasoning implementation
Mantis-Idefics2 (8B)
Core Architecture:
- 8B parameters
- Standard GPU requirements
- Consumer hardware compatible
- ~1-2GB per billion parameters
- 8K context window (LLaMA3 backbone)
Technical Innovations:
- Efficient instruction tuning pipeline
- Multi-image specialization
- Four-skill focus optimization
- Mantis-Instruct dataset utilization
Performance Metrics: The Numbers πGame
Benchmark Comparisons
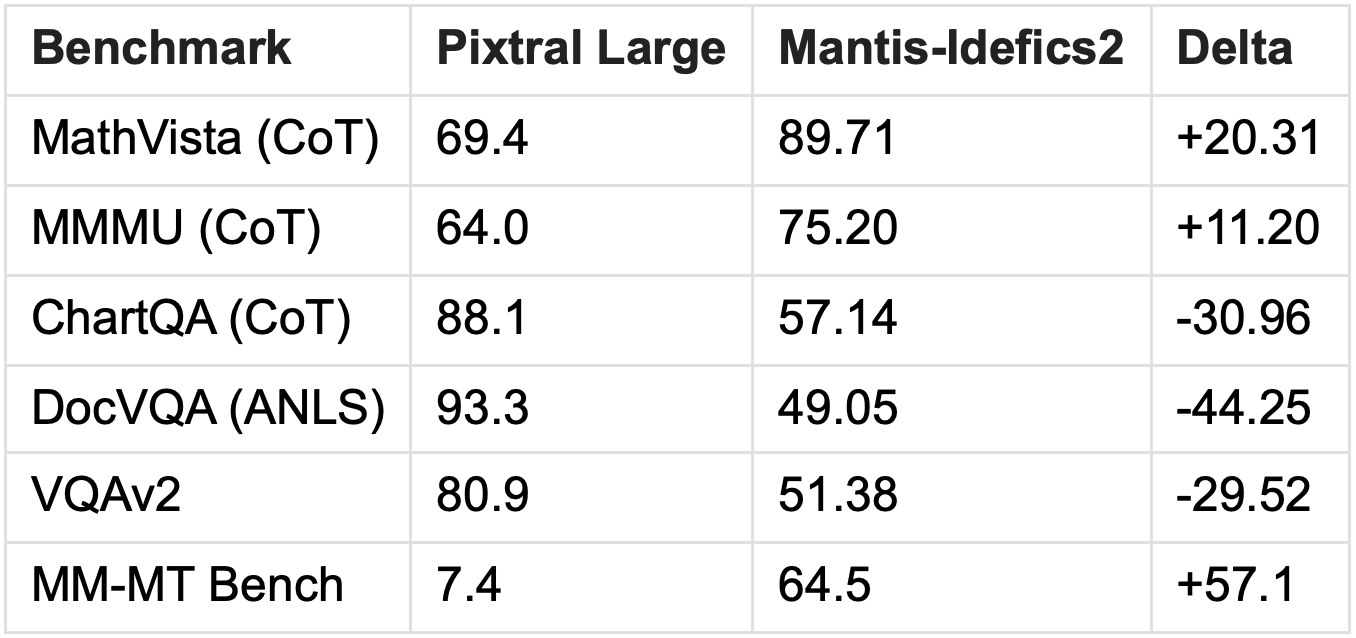
Note: Mantis-Idefics2 does not specify using CoT - inference time compute and result embedding centrality may play in its favor here
Efficiency Metrics
Resource Utilization:
- Pixtral: ~37.5GB per billion parameters
- Mantis: ~1-2GB per billion parameters
Deployment Options:∏
- Pixtral: Specialized data centers
- Mantis: Standard GPU infrastructure
The Reality Check: Beyond Research Metrics
Production vs. Research Considerations
1. Model Generalization
Larger models typically show better:
- Zero-shot performance
- Task adaptation
- Edge case handling
- Nuanced understanding
Historical precedent favors scale for generalization
2. Research Release Questions
- Is Pixtral Large identical to Mistral's production model?
- Are there unreleased optimizations?
- Could the 300GB requirement be pre-optimization?
3. Production Realities
Production models often employ:
- Model distillation
- Quantization
- Architecture optimizations
- Deployment-specific tuning
Hidden Complexities and Trade-offs
1. Scale Benefits
- Better generalization to unseen tasks
- More robust feature learning
- Greater adaptability potential
- Better handling of edge cases
2. Efficiency Concerns
Potential limitations in:
- Robustness
- Reliability
- Edge case handling
- Knowledge breadth
Technical Innovation Deep Dive
Pixtral's Approach
1. Architectural Choices
- Focus on flexible processing
- Native resolution handling
- Comprehensive reasoning capabilities
- Strong text model foundation
2. Computational Strategy
- Heavy pre-training emphasis
- Full reasoning implementation
- Architectural flexibility priority
- Text capability preservation
Mantis's Strategy
1. Efficiency Focus
- Built on proven architectures
- Optimized token handling
- Instruction-tuning emphasis
- Parameter efficiency priority
2. Training Innovation
721K carefully curated examples
Four-skill specialization:
- Co-reference mastery
- Visual comparison
- Multi-image reasoning
- Temporal understanding
Real-World Implications
Deployment Scenarios
1. Pixtral Large
- Limited deployment options
- High operational costs
- Complex scaling requirements
- Better for high-stakes applications
2. Mantis-Idefics2
- Flexible deployment
- Lower operational costs
- Easier scaling
- Suited for widespread adoption
The Efficiency Revolution
The efficiency-to-performance ratio reveals:
- Similar or better performance in many benchmarks
- Fraction of the parameter count
- Significantly lower memory requirements
- More practical hardware needs
Future Directions and Industry Impact
Development Priorities
1. Architectural Evolution
- Focus on token efficiency
- Balanced capability
- scaling Resource optimization
- Deployment flexibility
2. Training Methodologies
- Instruction tuning importance
- Dataset curation strategy
- Pre-training vs. fine-tuning balance
- Capability specialization
Market Considerations
1. Production Reality
- Real-world performance needs
- Operational cost management
- Scaling economics
- Market accessibility
2. Future Development
- Efficiency-first approaches
- Architectural innovation
- Specialized training methods
- Balanced scaling strategies
Conclusion: A Balanced Perspective
The comparison between Pixtral Large and Mantis-Idefics2 is more than just a technical face-off – it represents a philosophical divide in AI systems development that is critical for the future. While Pixtral Large boasts a comprehensive architecture capable of handling a wide range of general tasks, Mantis-Idefics2 demonstrates that clever training and efficient designs can achieve remarkable results with significantly fewer resources.
But the question we posed at the start remains: which model is right for your enterprise? There is no single correct answer. Each project is unique, and the model should be chosen based on the specifics of the task, which can range from small and narrow to large and general. Perhaps a hybrid approach could be the answer for many, allowing decisions on when each model is most appropriate. Our team can help you to decide.
The main lessons learned today are:
- Efficiency and scale both have their place.
- Real-world deployment differs from research.
- Balanced evaluation is essential.
- Continued innovation in both approaches is needed.
As we move forward, the industry would benefit from more comprehensive real-world testing, production metrics, and a deeper understanding of the trade-offs between generalization and efficiency. This is what we at ConfidentialMind are focusing on. We are constantly navigating the battle between compute-heavy and cost-efficient architectures, striving to deliver solutions where our customers win by balancing the best of both worlds. Only through such an approach will enterprise-wide adoption be possible - via an AI system that works out of the box, is efficient, and remains robust.
Greetings from our CEO

Markku Räsänen